Mar. 18, 2026
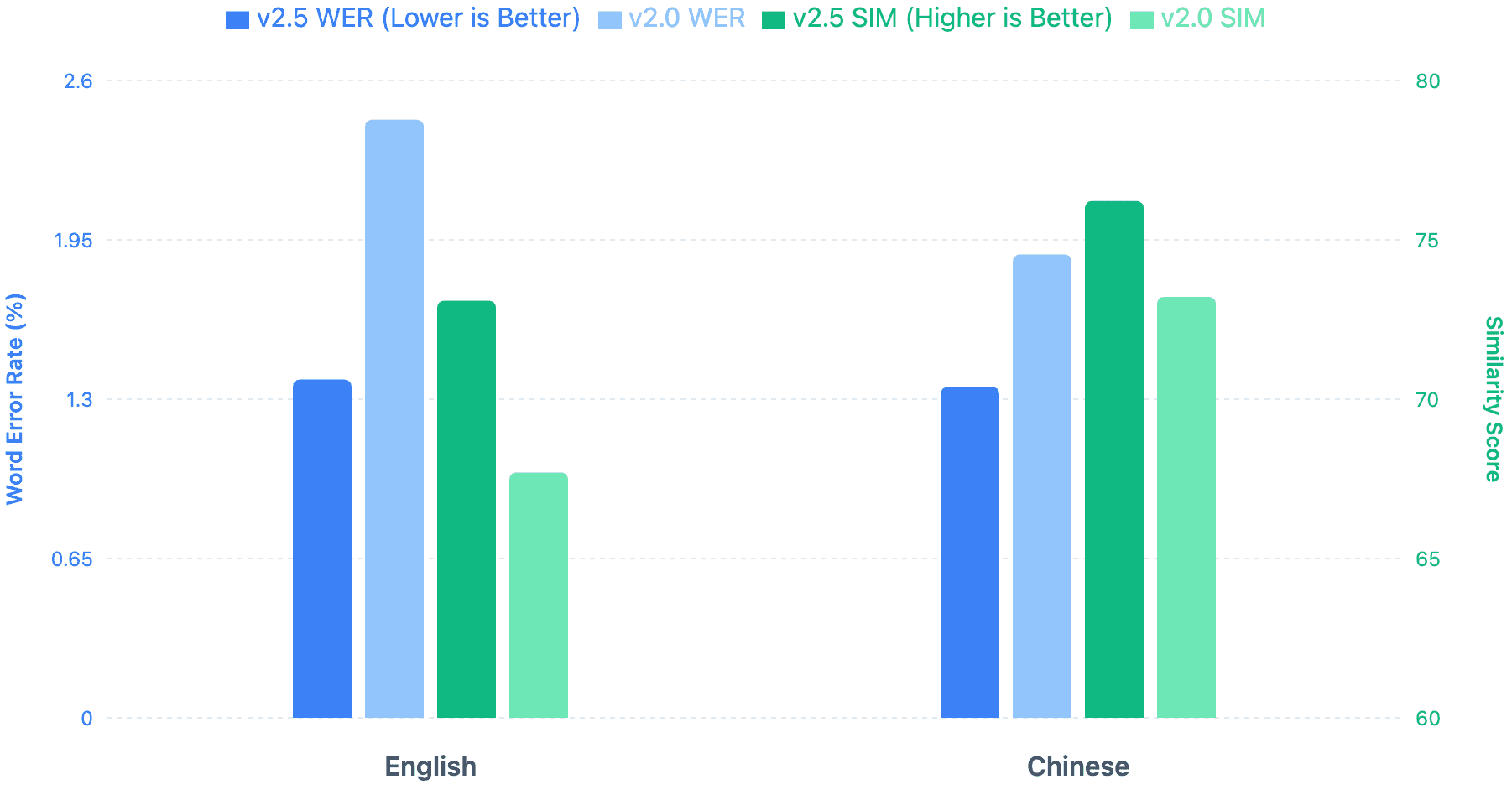
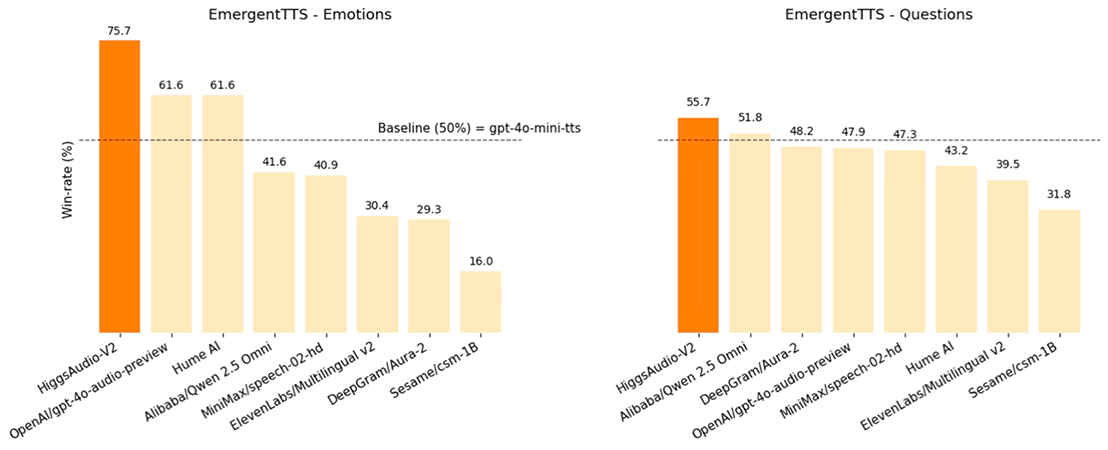
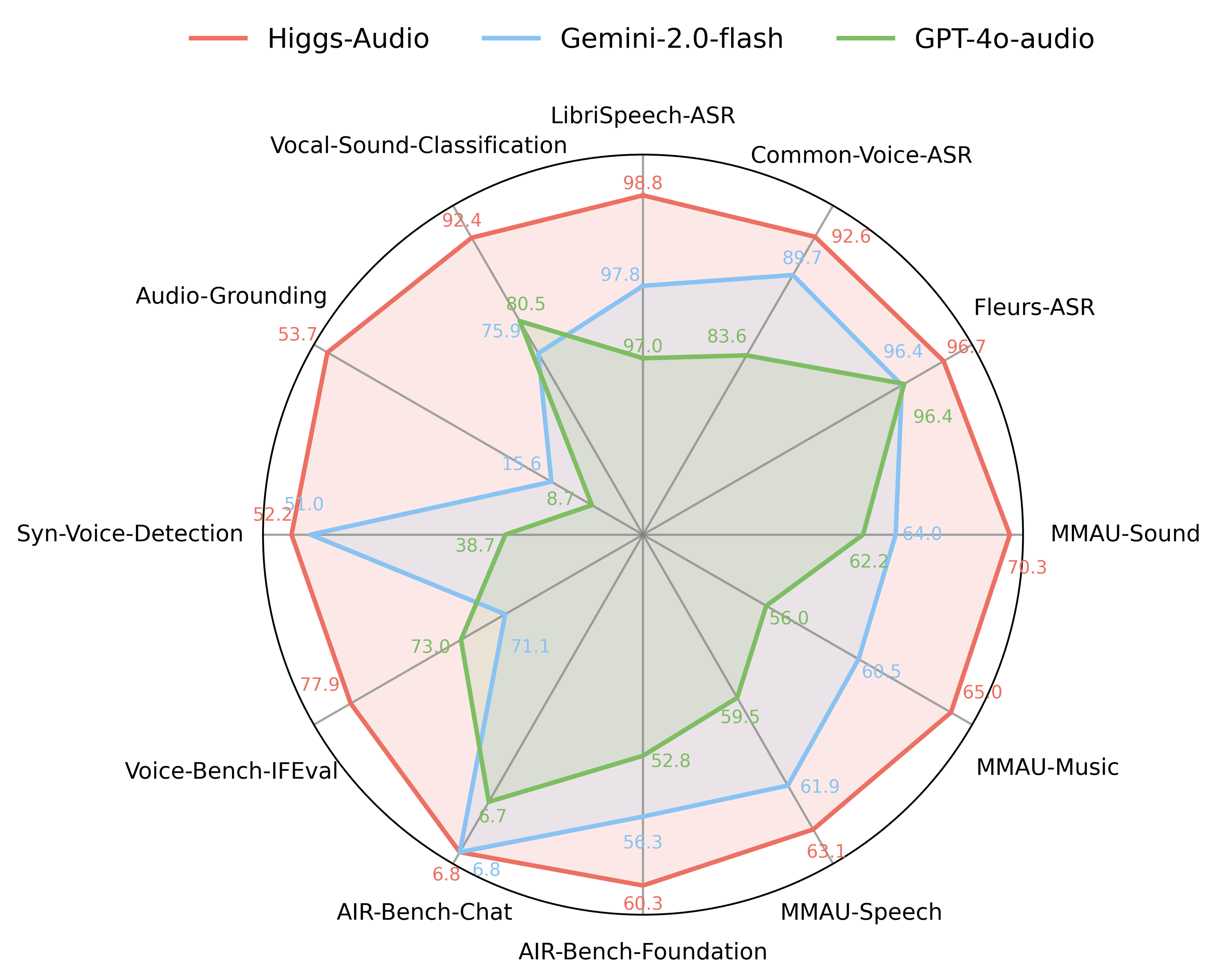
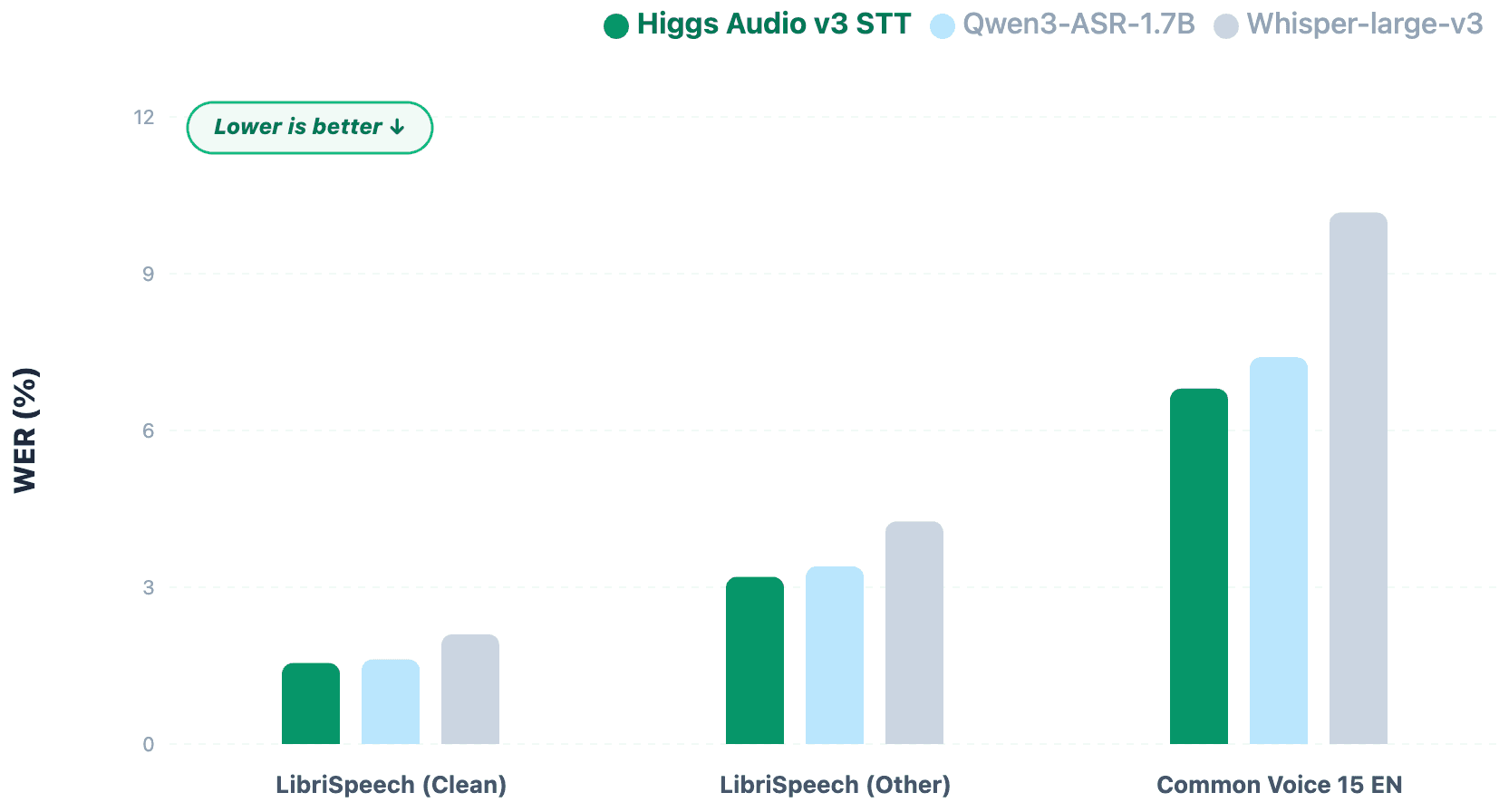
Boson AI Launches Higgs-Audio v3 Speech-To-Text ModelToday, we are publicly releasing Higgs Audio v3, a state-of-the-art Speech-to-Text (STT / ASR) foundation model. It supports 94 languages with sophisticated language detection, advanced sentiment and semantic understanding, and outperforms whisper-v3-large by a large margin on key languages.